Всем привет. В данной статье мне хотелось бы показать, как можно парсить контент с сайтов. Для этого мне потребуется программа Content Downloader 3, как раз получится заодно и ее обзор.
Для чего нужно парсить контент?
Если вы вебмастер, то вы уже скорее всего это знаете, если нет, то если вкратце, то это самый быстрый метод скопировать чужие новости для того, чтоб создать либо такой же сайт, либо похожий, либо похожий на основании какого-то либо путем переписания контента своими словами (путем рерайта.). На самом деле идей куда реализовать большое количество контента, пусть даже не уникального много и мы не будем их тут перечислять, а лучше сразу перейдем к методите быстрого добывания большого количества контента бесплатно.
Как вообще можно собрать контент бесплатно?! Можно найти сайт нужной тематики, а то и не один. Далее просто начать ручками копировать каждую новость с картинками и сохранять в отдельный файл. И так новость за новостью. Но сколько на это уйдет время?! Правильно, очень много! Поэтому это не наш случай, нам нужно много контента и максимально быстро. Именно поэтому нам и нужна программа Content Downloader 3.
Как быстро напарсить конент с сайтов с помощью Content Downloader 3
Для начала нам нужна программа Content Downloader 3. Сразу предупреждаю, что она платная, но она стоит своих денег. Но не стоит отчаиваться, так как у программы есть демо режим, который позволяет добывать контент не платив за программу, но есть ряд ограничений, который будет съедать ваше время, так как часть задач будет выполняться вручную.
Я лично сам, прежде чем купить программу опробовал ее в демо режиме и спарсил сайт в 768 новости минут за 30. Что явно раз в 10 превосходит тот вариант по скорости, если бы я делал это вообще вручную. Программа с лицензией выполняет эту операцию менее чем за минуту, это так – чисто для сравнения.
. Устанавливаем ее и запускаем.
1. Следующим нашим шагом будет поиск сайта нужной там тематики и с контентом, который нам подходит. Я для примера выбрал сайт тематики «Здоровье/Здоровый образ жизни/Медицина»
Под руку мне попался сайт-блог bienhealth.com

Хотелось бы рассказать мельком об одной интересной конторе которая специализируется на создании сайтов, их поддержке. Продвижение и раскрутка сайта – их конек, обращаетесь если есть необходимость.
Данный сайт подходит под выбранную мне тематику, содержит множество статей, красиво оформлен, статьи красивые и хорошо оформлены. То, что надо.
Сразу хочется предупредить, что если вам нужен контент с картинками, то вы должны выбирать сайты-жертвы, у которых на изображениях в контенте не стоят водяные знаки с адресом сайта. Иначе палево и результат будет выглядеть не так удачно.
Лично мне в данный момент не нужны картинки в изображении, поэтому мне все равно, но этот сайт попался без водяных знаков и мне подходит и так и так.
2. Вторым шагом будет определение как на сайте формируются страницы и как указать на них всех парсеру. Самый быстрый метод это указать парсеру карту сайта или блога, в которой как раз указаны ссылки на полезные статьи на сайте. То, что нам нужно! Карту сайта визуально порой не всегда можно увидеть, но у большинства сайтов адрес к карте сайта выглядит вот так : адрес сайта.ру/sitemap.xml
Поэтому я просто взял свой пример и указал ему bienhealth.com/sitemap.xml

Но тут меня ждала неудача. На сайте вебмастер разместил карту не по этому адресу или ее вообще нет. Чтож, я не отчаиваился и решил включить сперва голову и пробежался глазами по сайту в поисках нахождения за что можно зацепиться.
И что вы думаете? Я нашел в футере ссылку на страницу карты сайта - http://www.bienhealth.com/sitepages/

Но это карта сайта для пользателей и для поисковых пауков. Программа для парсинга ее не понимает. Тогда я еще пораскинул мозгами и решил посмотреть не указан ли адрес к карте сайта в файле robot.txt – и вуаля! По адресу http://www.bienhealth.com/robot.txt переходим и видим следующее:
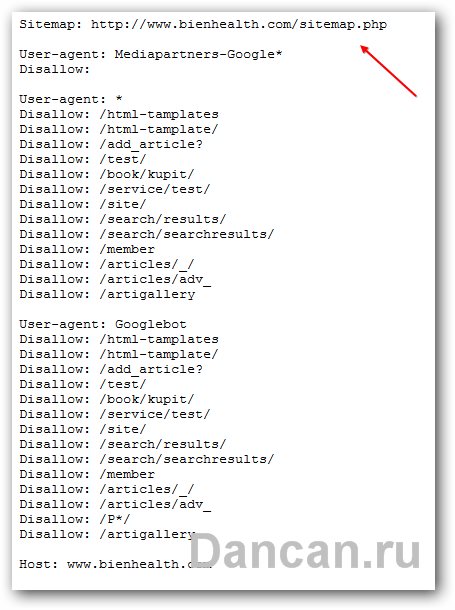
В данном файле мы видим ссылку на карту сайта с адресом http://www.bienhealth.com/sitemap.php. Переходим и видим следующую картину, а именно – мы видим, как браузер открыл файл sitemap.xml, но к сожалению, не видим где сам файл относительно сайта располагается, так как php скрипт прячет это от нас.

Но ничего, мы скармливаем прямо ссылку http://www.bienhealth.com/sitemap.php программе и наблюдаем как программа прекрасно скушала карту сайта и выдала нам результаты:
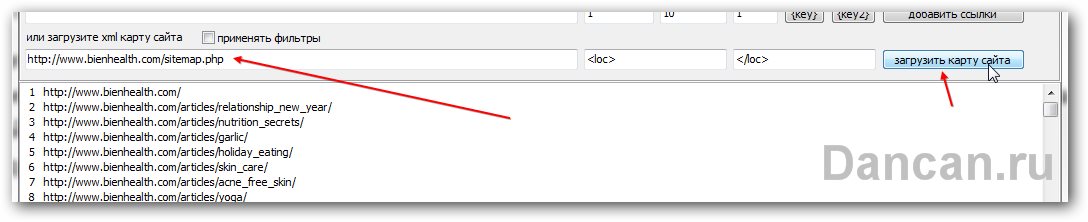
Теперь быстро пробегаем по результатам что выдала программа и пытаемся определить структуру сайта, чтоб понять быстро визуально ссылки, за которыми хранится контент, а за которыми ерунда хранится.
Сразу в глаза бросается в самом начале ссылка на главную страницу – она нам не нужна, сразу удаляем ее и смотрим дальше.

Теперь находим группу сайтов, у которых ссылка примерно одинаково формируется и отличается лишь заголовком статьи. Включаем мозговой штурм и группируем в голове записи с одной и той же структурой. Затем проверяем и кликаем дважды по паре ссылок из одной группе и смотрим какие страницы нам покажет программа.
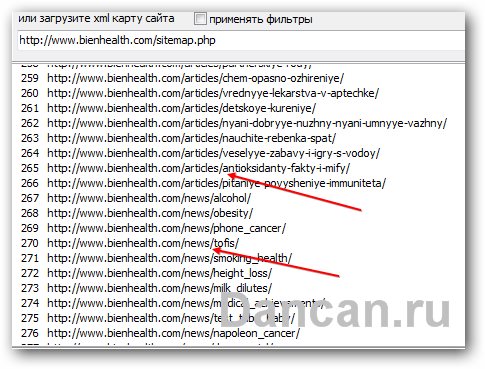
Например, я заметил что на моем сайте-жертве всего лишь 4 группы ссылок. Первая та что содержит в своем адресе слово articles. Кликаю 2 раза и вижу вот такую картину – вижу контент сайта, как раз то что нужно.
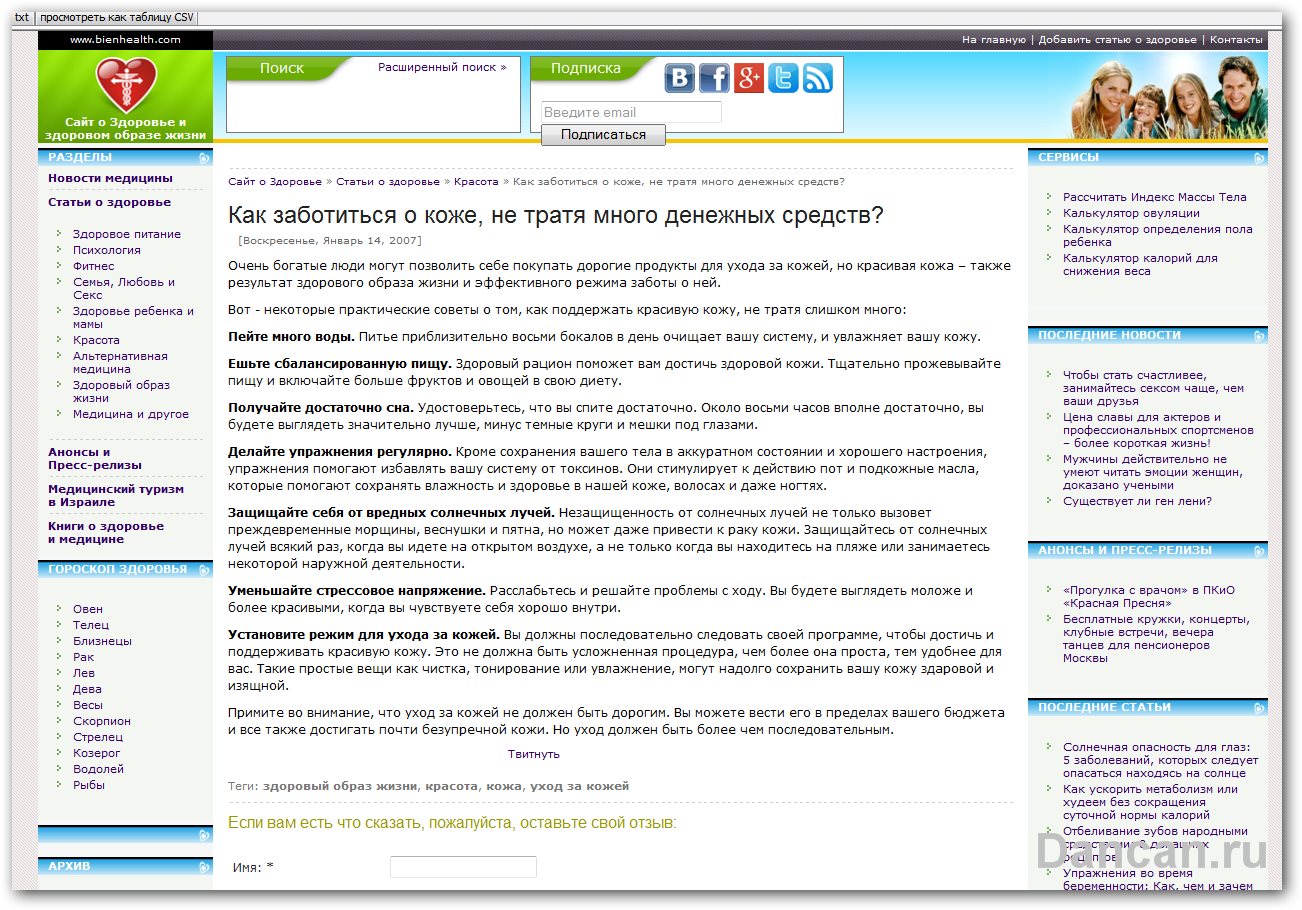
Потом есть ссылки со словом news. Кликаю – открываются тоже страницы с контентом. То что на надо.
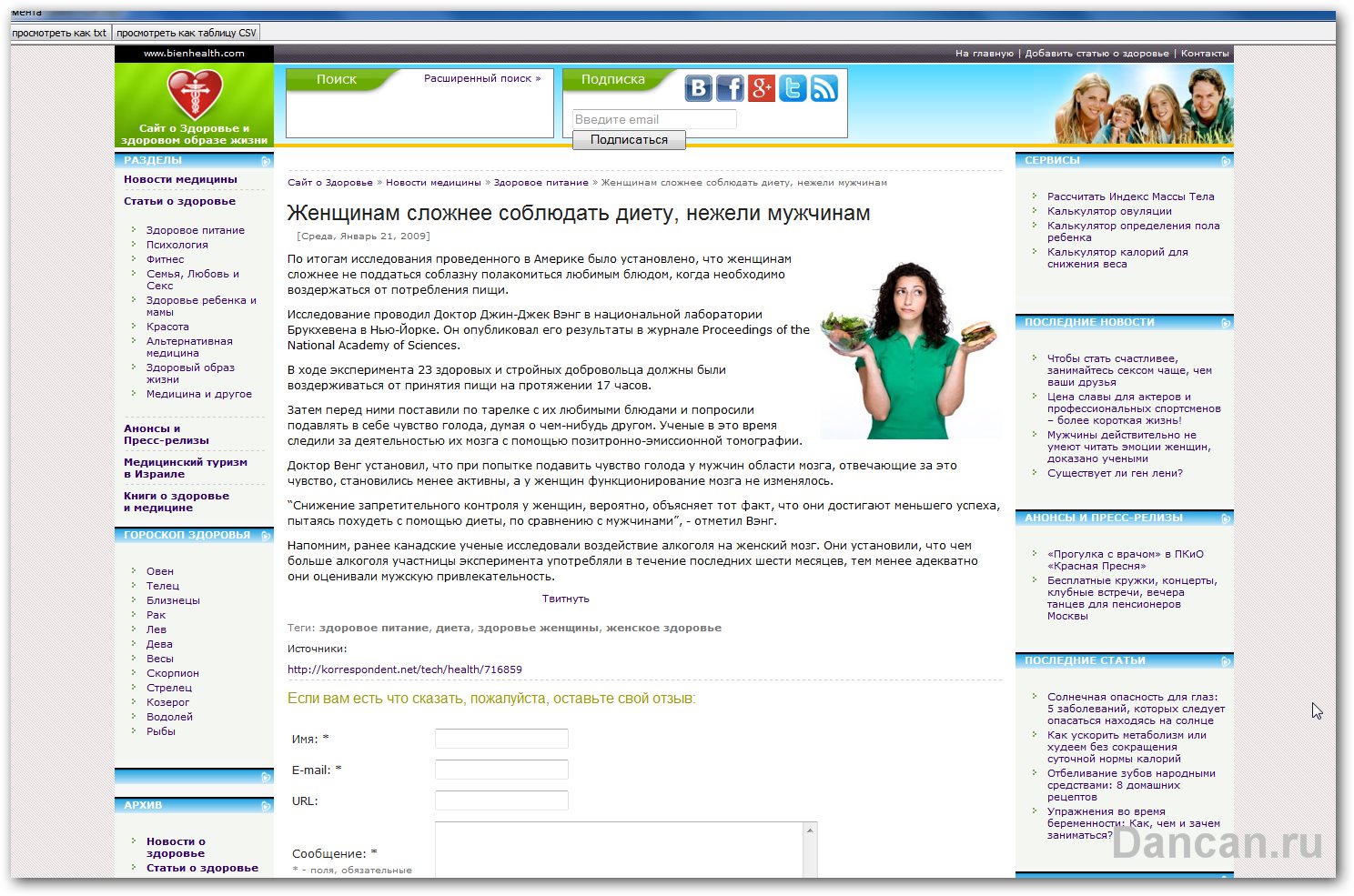
Следующей группой ссылок были ссылки содержащие слово book. Кликнув по такой ссылке – открывались ссылки с описанием на покупку книги с ее описанием. Мне лично такой контент не нужен и я обойдусь только статьями на тему здоровья и здорового образа жизни.
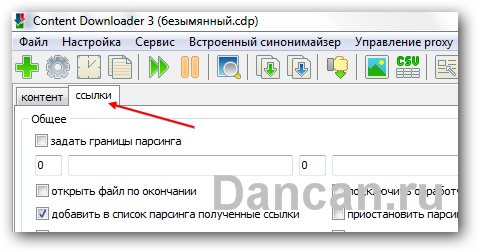
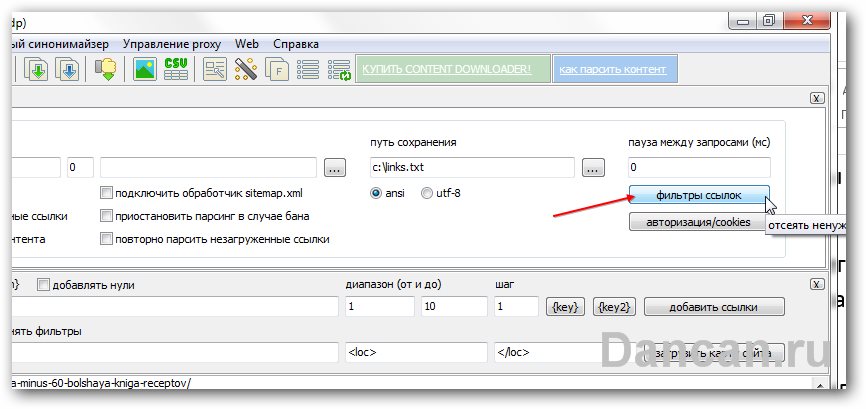
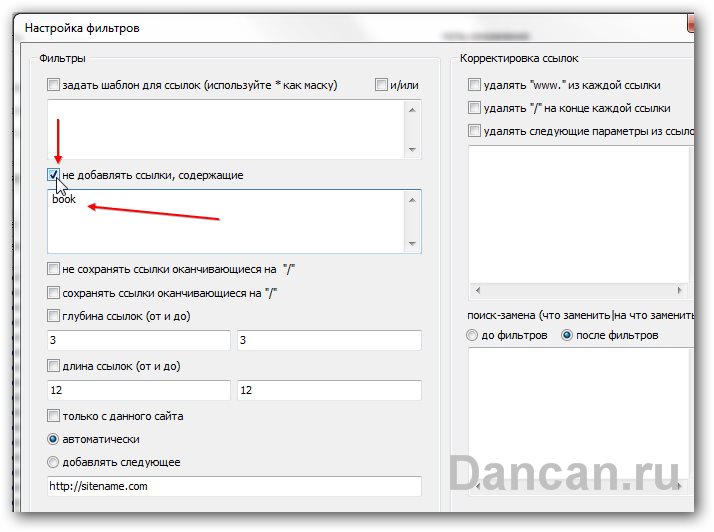
3. Поэтому моим следующим шагом будет удаление лишних ссылок со словом book – делать это в ручную далеко не приятная задача так как там их не одна сотня. Поэтому я нажимаю на вкладку «ССЫЛКИ». Затем нажимаю на кнопку «Фильтры ссылок» и ставлю галочку на чекбоксе «не добавлять ссылки со словами» и вписываю в текстовое поле слово book. Далее нажимаю кнопку “готово» внизу.
Теперь нужно просто на полученных ссылках нажать правой клавишей мыши и выбрать «Применить фильтры к списку ссылок» и вуаля – все готово.

4. Последней группой ссылок были у меня ссылки со словом anons, но их было всего 2 поэтому я решил их просто удалить
На выходе у меня получилось 768 ссылок с контентом.
5. Теперь нам нужно определиться что именно из этих страниц нам парсить, ведь на страницах помимо контента очень много всего лишнего.
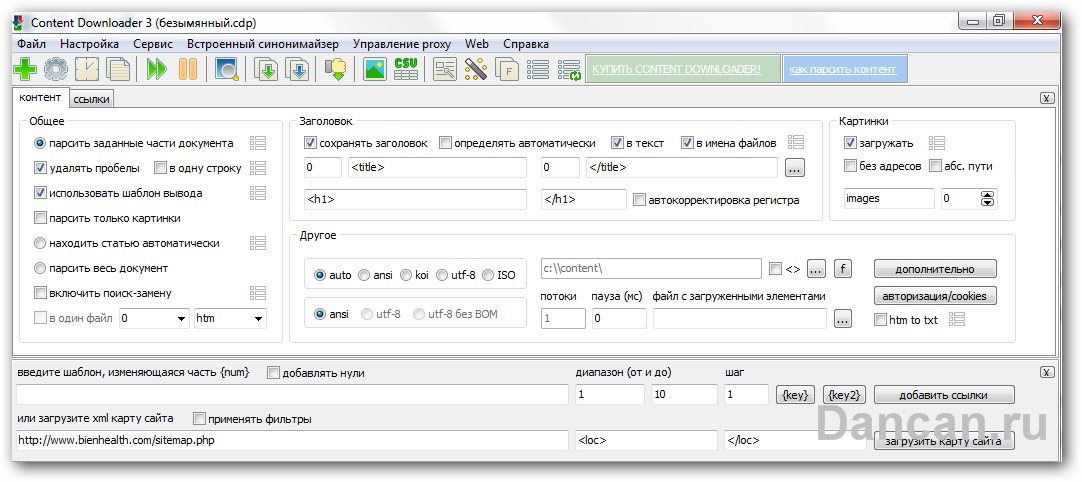
Переходим в верхнюю часть программы и выставляем галочки так, как указано снизу на скриншоте.
Затем жмем вот на эту кнопочку
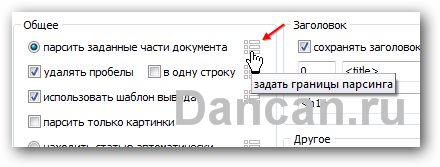
И перед нами откроется вот такое окно программы, с помощью которого можно настроить что и как парсить. Вид, структуру, расположение и прочее полученного контента вы выбираете сами, поэтому тут зависит от целей и желаний каждого, поэтому я покажу вам самый простой вариант, которого достаточно для того чтоб импортировать контент в Зеброид или сразу же в WordPress.
Мы парсим имена категории, к которой относится та или иная статья и затем парсим заголовок статьи, затем сам контент. Так же разрешаем программе парсить изображения.

Чтоб настроить что и как парсить программе, то переходим по вот этой кнопке

Перед нами откроется большое окно, в котором будет виден исходный код страницы сайта, в котором не опытному пользователю будет ничего не понятно. Но я же пишу простую инструкцию, для новичков чтоб подходила, поэтому подсказываю – внизу есть кнопка «Открыть браузер». Жмем на нее и станет уже легче.
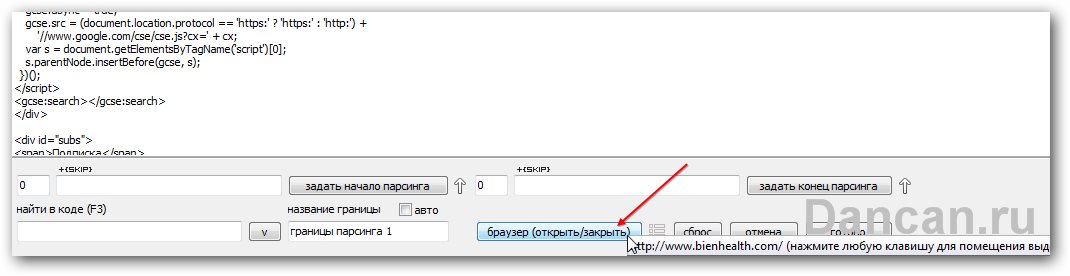

Далее опять включаем голову – нам нужны категории, к которой данная статья относится. Ее я замечаю в хлебных крошках абсолютно в любой из статей на сайте – то что нам надо. Теперь кликаем по названию категории, в моем случае слово «красота». Программа сразу же подсветила строку

<a href="http://www.bienhealth.com/article/C5/" itemprop="articleSection">Красота</a> » Деликатный уход за глазами</span>
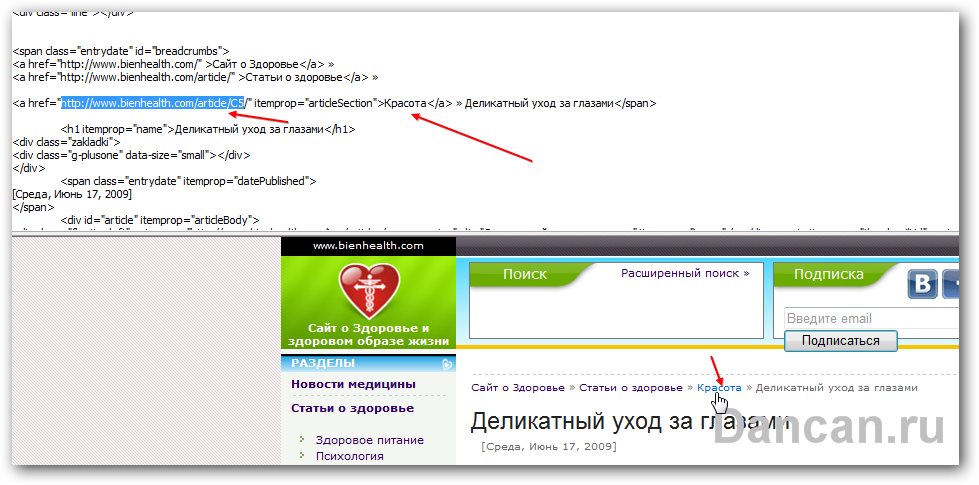
Мозги включены? Если да то можно понять что строка с самой ссылкой и само название категории «http://www.bienhealth.com/article/C5/» и соответственно слово «Красота» будут меняться в зависимости от статьи, если она из другой категории. А вот обрамление вокруг слова «Красота» - itemprop="articleSection"> и </a> » меняться не будут не зависимо какая статья и из какой категории она выбрана. Это якорь, за который мы и ухватимся. Теперь показываем этот кусок кода, который не будет меняться в независимости от статьи.
Выделяем первый кусок кода и жмем внизу «задать начало парсинга», затем выделяем второй участок кода и жмем «задать конец парсинга» и жмем готов. Все, пеперь программа знает откуда в каждой статье брать категорию.


Заголовок статьи программа умеет определять сама без проблем, поэтому нам нужно теперь указать программе границы начала и конца самого контента.
Опять заходим внутрь статьи в программе и кликаем на начало контента и ищем тег, за который можно зацепиться. В моем случае я нашел начальный тэг, но учитывая, что он является div, то достаточно начального, так как программа умеет сама определять где он закончится, если мы поставим вот такую галочку и просто напишем название тэга без всяких там скобок. См. скриншот ниже.

6. Теперь нам надо настроить шаблон, как результаты нашей работы должны выглядеть и в какой последовательности. Жмем кнопку настройки шаблона и выставляем там все как у меня на скриншоте. Не нравится как у меня – ваша фантазия вам поможет реализовать так, как вам хочется. Программа очень богата функционалом!

Теперь если я просто нажму на любую из ссылок, что программа мне достала в самом начале то я буду видеть вот такую вот картину.

Как раз то что над – имя категории, затем название статьи и сама статья с изображениями. Красота! Все чисто и только то что нужно.
Теперь осталось только указать папку куда складывать результаты работы и нажать кнопку «ПАРСИТЬ».
Если нажать то вот что получится – в папочке по умолчанию что указана появится файл с вашей статьей что вы напарсили и папка с изображениями, если вы указали их парсить тоже (мне изображения не нужны). Программа если куплена, то обработает все ссылки что у вас есть, если демо режим, то по одной – причем запускать придется вручную каждую ссылку, но что уйдет много времени.
Теперь еще можно все это наше месиво сгруппировать по категориям, удалив из статьи первую строку, в которой как раз и находится название категории и создать папочку с ее наименованием и положить все статьи в нужные папки в зависимости от категории.

Для этого смотрим на скриншот и делаем все как там указано стрелочками в той же последовательности.

Вот теперь у нас на выходе большое количество статей, каждая из них лежит в своей папочке с названием категории. Теперь остается только решить что с ними вы будете делать – импортировать в WordPress, закидывать в Зеброид или еще как. Это ваше дело.
Мое мнение о парсинге контента и программе Content Downloader 3 в целом: парсинг - это самый быстрый метод добычи большого количества с сайтов. Достаточно 1 раз для каждого сайта настроить шаблон для парсинга, на что уйдет 10 минут, и затем программа за считанные секунды обработает вам сотни, тысячи и даже десятки тысяч страниц, обработает их и сохранит вам в удобном для вас виде. Если это делать руками, то на выполнение этих операций уйдут часы, дни, а то и даже недели.
Программа Content Downloader 3 обладает очень широким функционалом, который предоставляет невероятно большие возможности по парсингу любых материалов с любых сайтов. Программа продолжает развиваться и набирать популярность!
Всем рекомендую!